
Last year, Mozilla started a grand project with a noble aim — to make an open-source, publicly available dataset that can be used by any speech-recognition software.
In a world where technology giants like Google, Apple, and Amazon are each trying scrambling to create their own ecosystems with their own, private, machine-learning datasets, the Mozilla Foundation has a novel idea up its sleeve.
Mozilla Common Voice
To create or recognize speech, an extremely large data set is required which isn’t exactly feasible for small, independent developers. And the companies that do have prowess in this field don’t exactly have your best interests at hearts and are more focused on their own profits.
ALSO READ
New Sound Tech Could Make Headphones Obsolete
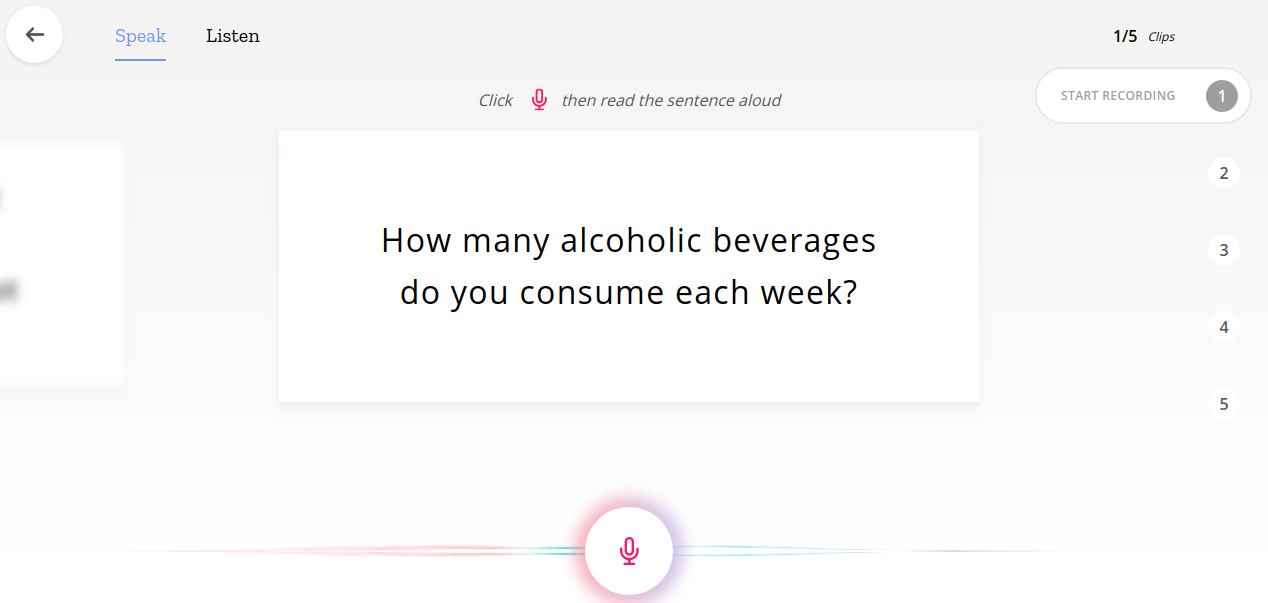
Mozilla’s Common Voice is a project that allows anyone to contribute by speaking a sentence and letting their software record and process it. It is then analyzed and synthesized, using complex, machine learning algorithms.
It is open for anyone to participate. All you need to do is just head over to the contribute section on their website, hit the “Start Recording” button and read out the text shown to you in the card. You can also download its mobile app through the App Store.
Why You Should Contribute
Late into 2017, Mozilla showed why this project matters by releasing the second biggest publicly available voice dataset! A collection of 400,000 recordings from 20,000 people, it resulted in about 500 hours of speech that can be downloaded by anyone. They have even developed an open source Speech-To-Text engine called DeepSpeech, using a model trained by machine learning techniques, based on Baidu’s Deep Speech research paper, and Google’s TensorFlow platform.
This is why it is really important to make sure that Mozilla’s project succeeds. Not only does it open doors for small startups but it also encourages competition and levels the playing field just a little bit more.
Moreover, it is also important for us to contribute as Pakistanis. Although the project isn’t available for Urdu language (it just expanded to include French, German and Welsh), one problem I have come across in almost every voice-based assistant is the trouble it has in understanding English spoken with a Pakistani accent. Today, this problem may not be as annoying as it was a few years ago, thanks to the lightning pace at which speech recognition has been improved, but it is still important to address it.
Being a free and amazing resource, a lot of developers are going to use this dataset in their own systems. Pakistanis need to take part in this project to give their voice (literally) as it is the only way to make speech systems more inclusive and better configured to be used by the people of this country.
Stay Connected with ProPakistani
Get the latest tech news, telecom insights, and product launches wherever you prefer.
Add ProPakistani to Preferred Sources and see more of our stories in Google Search and Top Stories.












