
Lately, there’s been an unexpected observation regarding GPT-4’s performance degrading over time, rather than improving. The consensus about the decline in the AI model’s response quality, though initially based purely on individual experiences, has now gained empirical support.
This has now been proven by new research.
Recent studies have demonstrated that the June variant of GPT-4 has a notably poorer performance than the March version when it comes to certain tasks. To exemplify, a set of 500 problems was administered, requiring the model to identify if a given integer was prime.
The results were concerning. The March model accurately solved 488 problems, but the June model could only muster 12 correct responses. This indicates a stark fall in accuracy, from an impressive 97.6% to a dismal 2.4%!
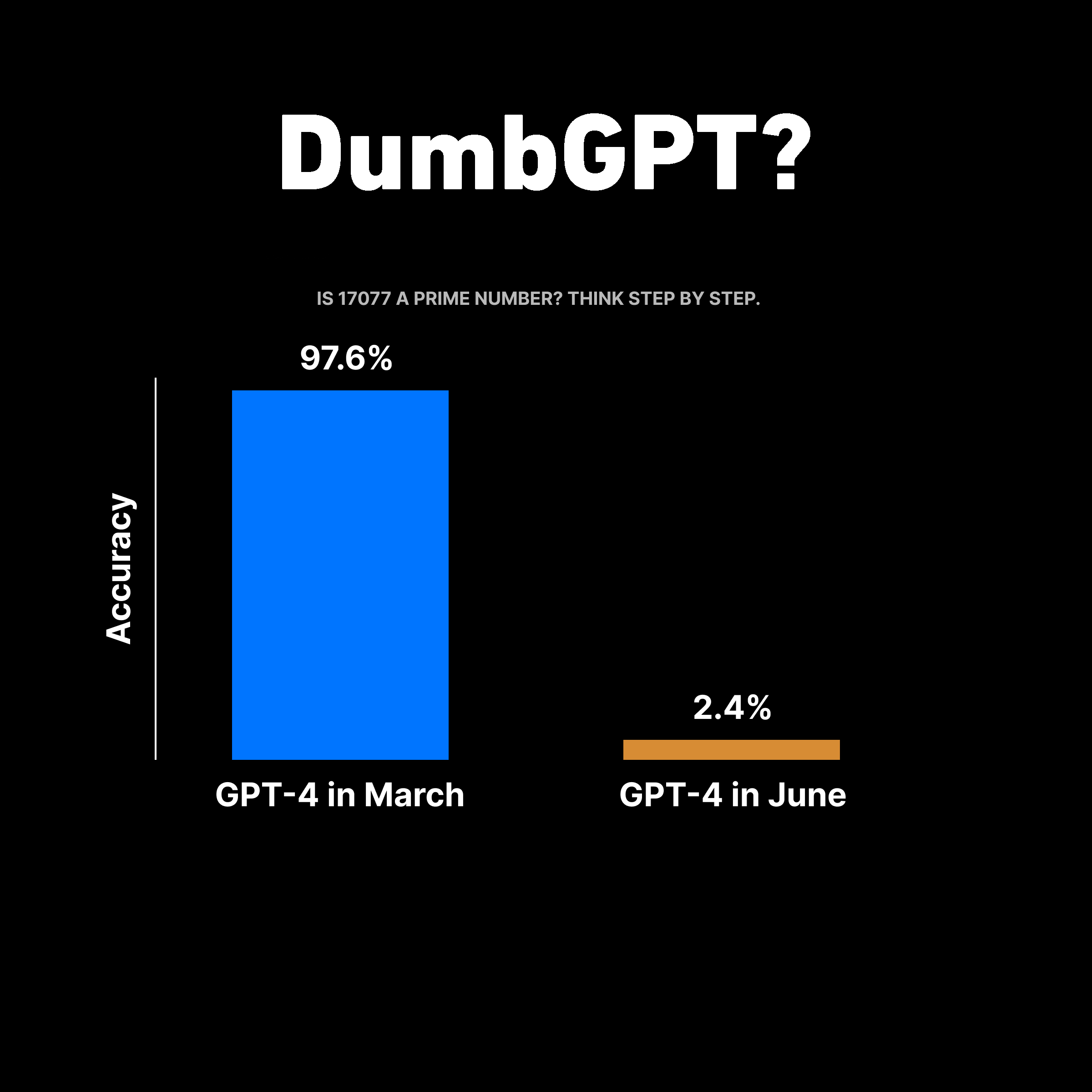
The scientists attempted to boost the model’s analytical capability using the Chain-of-Thought method. This involved prompting the model to break down the task of determining if ‘17077’ is a prime number into simpler, step-by-step calculations. This method usually enhances the quality of the model’s outputs. However, the updated version of GPT-4 was unable to generate these intermediate steps, leading to an incorrect response of “No.”
Moreover, the model’s capacity to produce code has also seen a significant decline.
We can only speculate on the root cause of this issue.
While it’s generally understood that OpenAI regularly pushes out updates, the exact methods they utilize to gauge the progress or regress of the model remain obscure. Speculation abounds that OpenAI might be utilizing multiple, more specialized, and smaller GPT-4 models that replicate the functions of a large model, but with reduced operational expenses. When a user submits a query, the system selects the most appropriate model to process the request.
This strategy is certainly more cost-effective and quicker, but could it be a factor in the decline in output quality?
This serves as a warning to developers who incorporate GPT-4 into their applications. It’s not viable for the behavior of a Language Learning Model to vary inconsistently over time.
Source: Medium
Stay Connected with ProPakistani
Get the latest tech news, telecom insights, and product launches wherever you prefer.
Add ProPakistani to Preferred Sources and see more of our stories in Google Search and Top Stories.










