
Google has introduced DiffusionGemma, an experimental open model designed to generate text faster by using a diffusion-based approach instead of the usual token-by-token method used by most large language models.
The model has been released under the Apache 2.0 license. It is a 26B Mixture of Experts model, but only 3.8B parameters are active during inference. Google says this allows DiffusionGemma to run within 18 GB of VRAM limits on high-end consumer GPUs when quantized.
The model is built on the Gemma 4 family and Google’s Gemini Diffusion research. Google says DiffusionGemma can deliver up to 4x faster text generation on GPUs, but it is still experimental and is not meant to replace standard Gemma 4 models for high-quality production work.
What Makes It Different
Most language models generate text from left to right, one token at a time. This works well in cloud systems where servers can process many user requests together, but it can leave local GPUs underused when serving one user at a time.
DiffusionGemma works differently. It generates 256 tokens in parallel with each forward pass, allowing the model to draft a full block of text at once and refine it over multiple steps.
Google says this approach shifts the bottleneck from memory bandwidth to compute, which helps improve speed on dedicated GPUs. The model can generate more than 1,000 tokens per second on a single NVIDIA H100 and more than 700 tokens per second on an NVIDIA GeForce RTX 5090.
Speed and Trade-Offs
DiffusionGemma is aimed at researchers and developers working on speed-sensitive local workflows. These include in-line editing, rapid iteration, non-linear text generation, code infilling, amino acid sequences, and mathematical graphs.
The model uses bi-directional attention, meaning every token in a generated block can attend to all other tokens. This helps in tasks where earlier and later parts of the output depend on each other.

It also supports iterative self-correction. The model can review the full text block and refine its own output during generation.
However, Google says DiffusionGemma’s overall output quality is lower than that of standard Gemma 4 because it prioritizes speed and parallel layout generation. For applications that require the best output quality, Google recommends standard Gemma 4 models.
Local AI Use
Google says DiffusionGemma’s speed advantage is strongest for local and low-concurrency inference.
In high-QPS cloud serving, autoregressive models can already use batching to keep hardware fully active. In those cases, DiffusionGemma’s parallel decoding offers smaller benefits and may increase serving costs.
The model is therefore better suited to low-to-medium batch sizes on a single accelerator, especially for local tools and interactive AI applications.
How Text Diffusion Works
DiffusionGemma applies a diffusion-style process to text generation.
The model starts with a canvas of random placeholder tokens. It then makes multiple passes, locking in correct tokens and using them as context to refine the rest of the output. The process continues until the text reaches its final form.
Google says this allows the model to support patterns that are harder for sequential models, such as closing complex markdown formatting correctly or generating and rendering code in near real time.
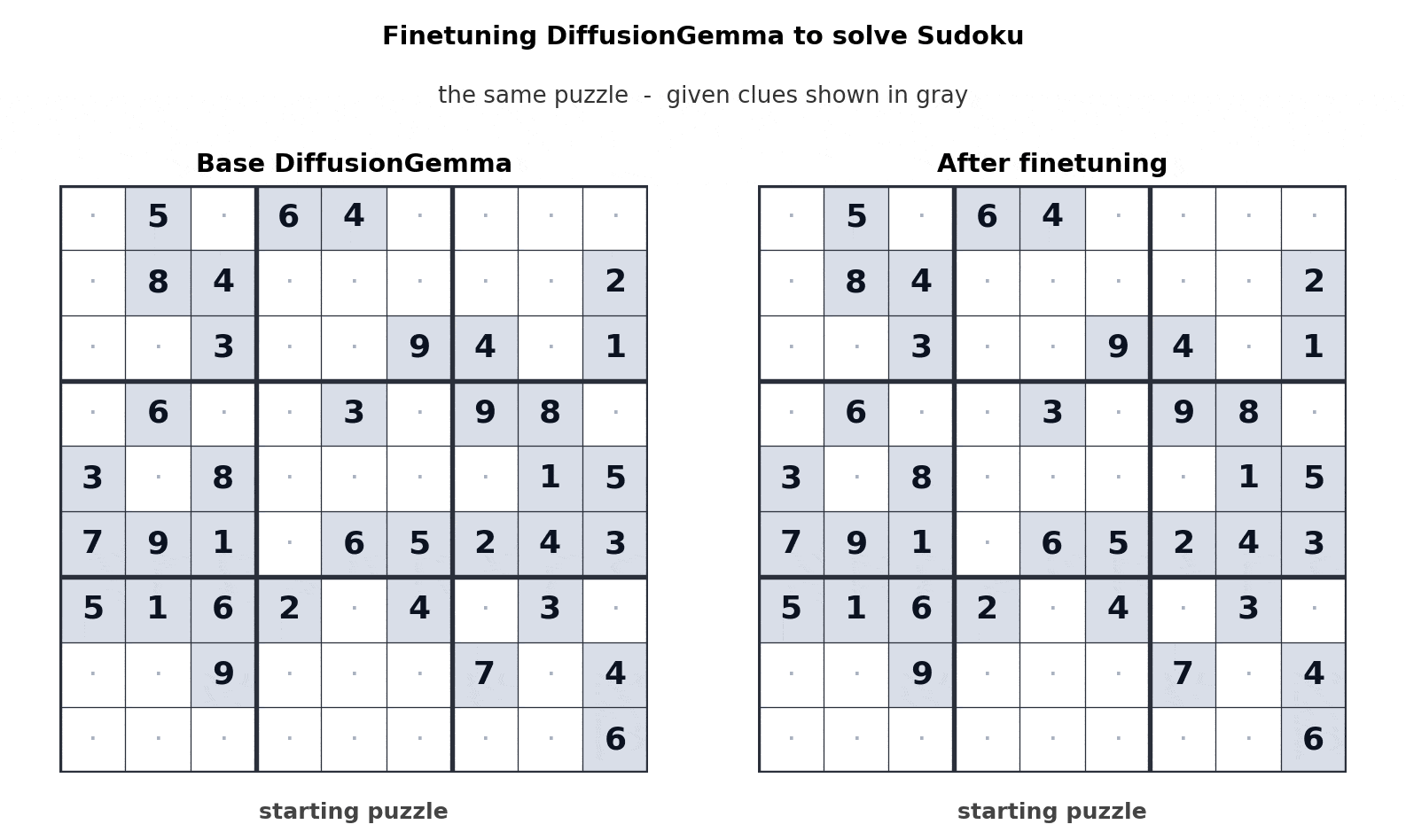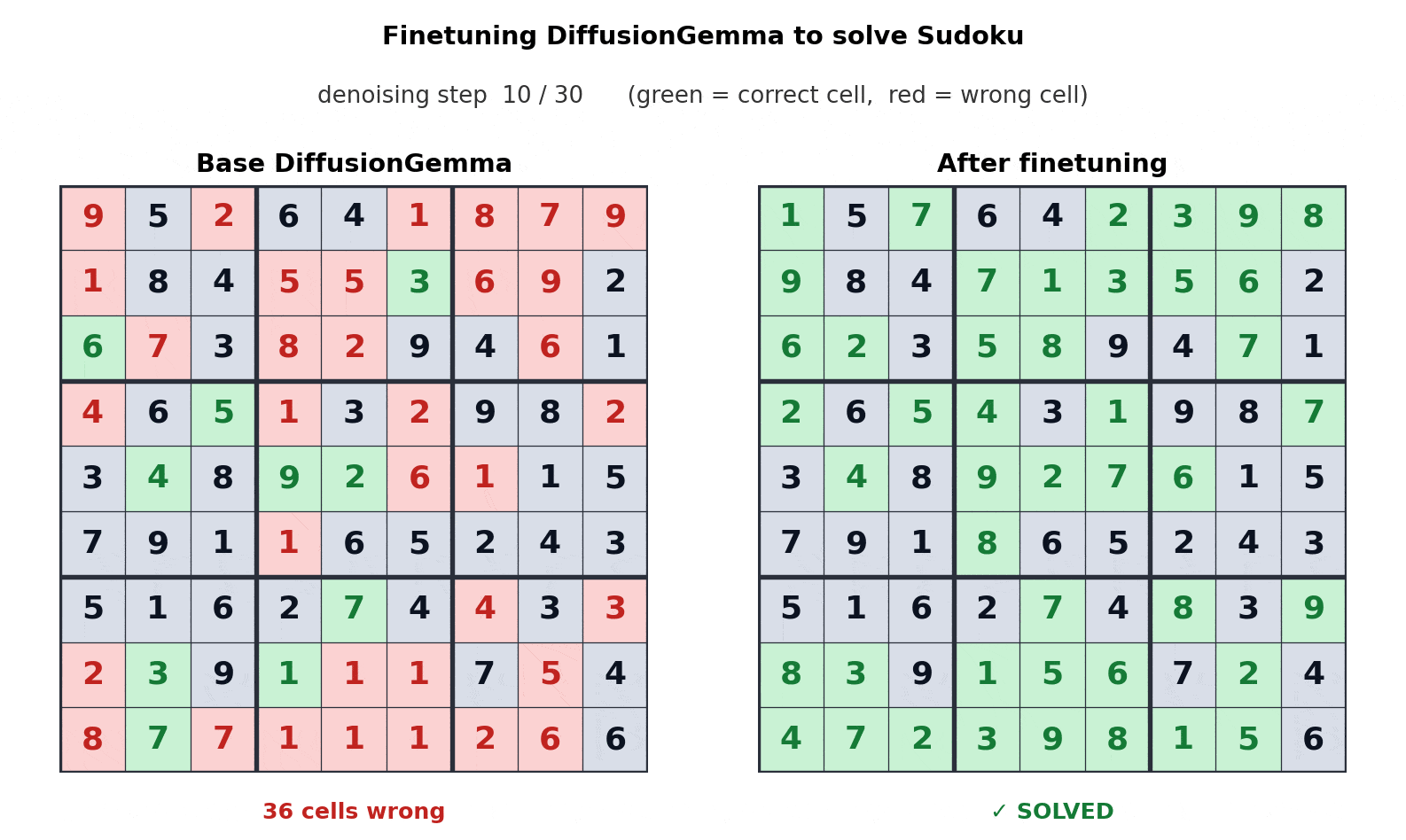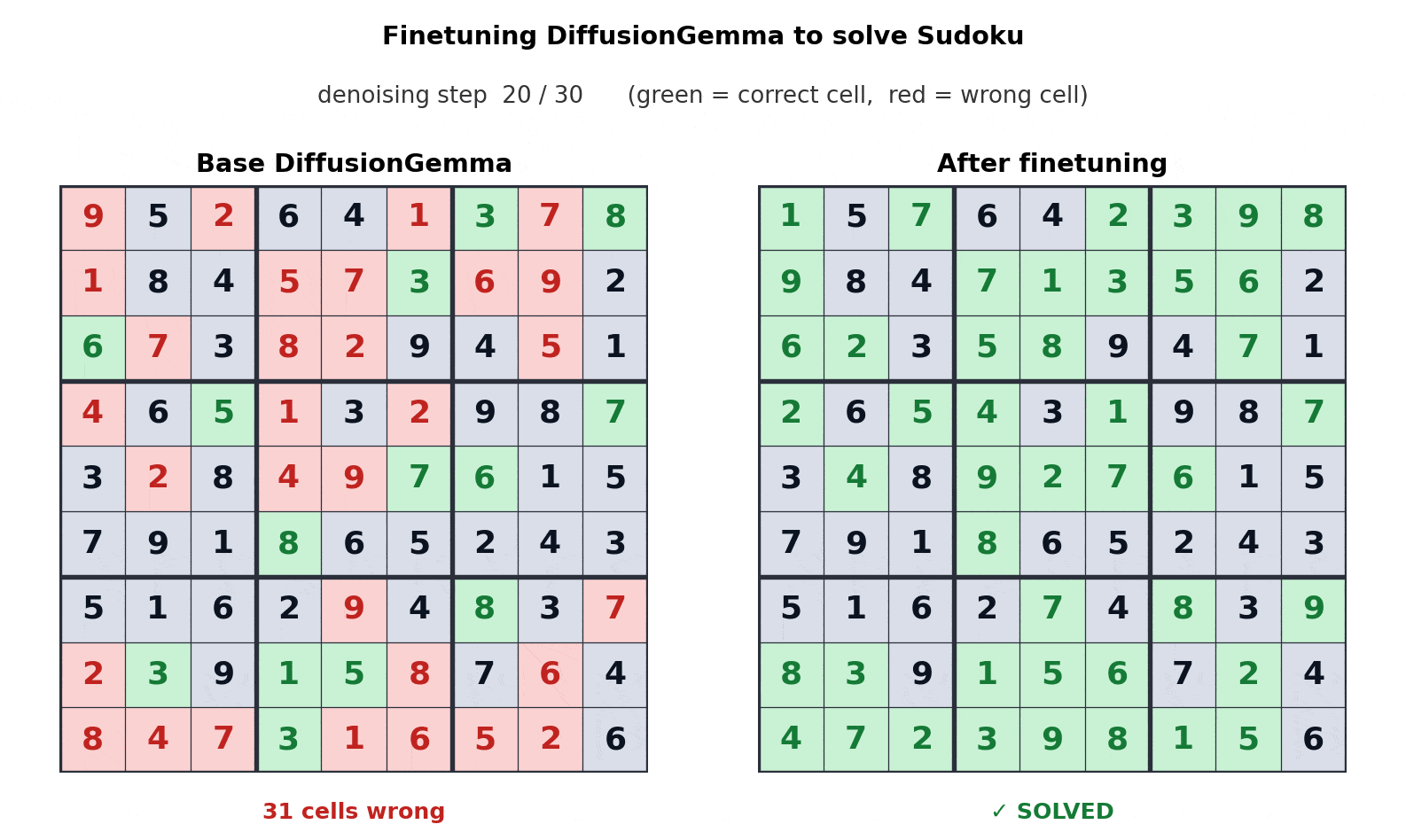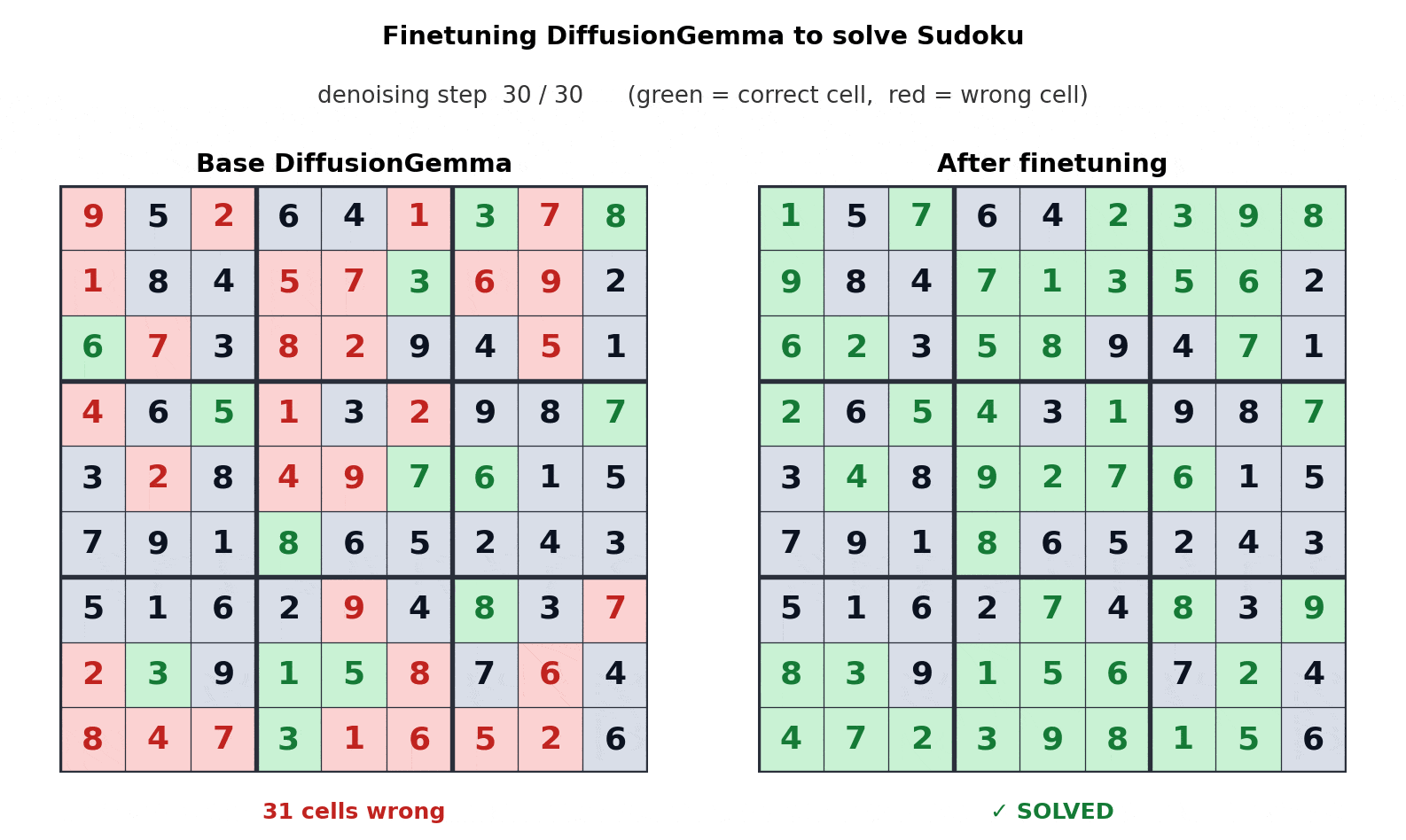
Fine-Tuning Example
Google says DiffusionGemma can be fine-tuned for specific tasks.
In one example, Unsloth fine-tuned DiffusionGemma to play Sudoku. Google says this is a task where autoregressive models can struggle because each token can depend on future tokens.
DiffusionGemma’s bi-directional attention makes that type of task easier because the model can consider the full text block at once.
Developer Tools
Developers can download DiffusionGemma’s experimental model weights from Hugging Face under the Apache 2.0 license.
Google is also providing a developer guide and a visual guide explaining how DiffusionGemma works.
The model can be served through MLX, vLLM, and Hugging Face Transformers. Google says vLLM integration is supported by Red Hat.
For fine-tuning, Google is releasing a tutorial using Hackable Diffusion, a modular JAX toolbox. Developers can also explore fine-tuning with Unsloth and NVIDIA NeMo.
Official support for llama.cpp is also planned.
NVIDIA Optimization
Google says it worked with NVIDIA to optimize DiffusionGemma across NVIDIA hardware.
The model is quantized for consumer GPUs such as the GeForce RTX 5090 and RTX 4090. It also supports enterprise systems using Hopper and Blackwell hardware with advanced NVFP4 kernels.
Google also mentioned support for NVIDIA DGX Spark, DGX Station, and RTX PRO systems.
Native support for NVFP4, a 4-bit floating-point format, is designed to improve compute throughput while keeping accuracy close to the original model.
Stay Connected with ProPakistani
Get the latest tech news, telecom insights, and product launches wherever you prefer.
Add ProPakistani to Preferred Sources and see more of our stories in Google Search and Top Stories.












